Déverrouiller la Précision : Plongée dans l'Architecture RAG
Les Modèles de Langage (LLM) ont révolutionné l'accès à l'information, mais ils souffrent d'un mal connu : les hallucinations et un manque de connaissance spécialisée. Comment garantir qu'une réponse complexe, par exemple sur l'optimisation avancée des nœuds Lightning, est non seulement bien formulée, mais surtout correcte et fiable?
La réponse réside dans le RAG (Retrieval-Augmented Generation – Génération Augmentée par Récupération). Chez dazno.de, nous avons implémenté cette architecture modulaire via la classe RAGWorkflow (dans le système MCP) pour transformer un simple LLM en un expert thématique, capable de s'appuyer sur un corpus de connaissances contrôlé.
Voici comment ce puissant pipeline est construit et opère, divisé en deux phases maîtresses.
Phase I : L'Indexation – Construire le Cerveau de Connaissances 🧠
L'objectif de cette phase est de préparer les documents bruts pour la recherche sémantique. C'est l'étape où le texte devient "intelligent".
1. Ingestion et Découpage (Chunking)
Nous commençons par ingérer des documents texte bruts. Pour garantir une recherche et une transmission optimale au LLM, les documents sont méticuleusement découpés :
- Taille des Chunks : 512 tokens. C'est le point d'équilibre pour encapsuler une idée complète sans surcharger.
- Chevauchement : Un chevauchement de 50 tokens est appliqué entre les fragments. Cette technique assure que le contexte autour des limites de découpage n'est pas perdu.
- Enrichissement : Chaque fragment est enrichi de métadonnées essentielles (source, date, contexte) pour la traçabilité et le filtrage.
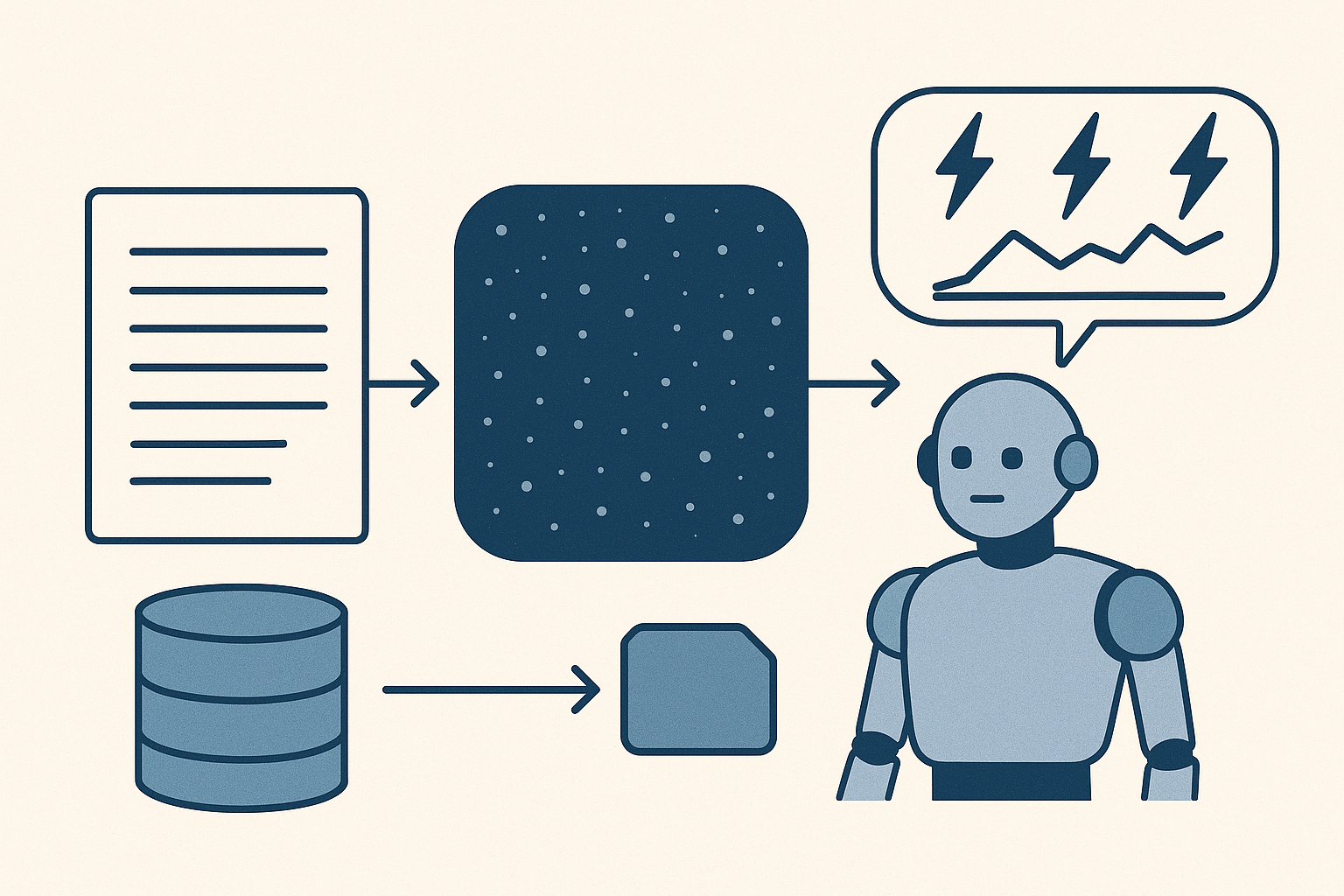
2. Le Passage au Numérique : Génération d'Embeddings
Pour que les machines puissent "comprendre" le sens d'un chunk, le texte doit être converti en une représentation numérique.
- Modèle de Vectorisation : Nous utilisons le modèle de pointe "text-embedding-3-small" d'OpenAI.
- Dimension : Chaque fragment est transformé en un vecteur de 1536 dimensions. Ces vecteurs sont la clé de la recherche sémantique : deux vecteurs proches dans cet espace signifient que les textes sont proches en termes de sens.
- Optimisation : Pour l'efficacité, la génération des embeddings est optimisée via le traitement de lot (batching), réduisant les appels API.
3. Stockage et Vitesse : MongoDB et FAISS
Les données traitées sont stockées dans une architecture hybride optimisée :
MongoDB : Stockage persistantConserve les documents originaux, les métadonnées et l'historique des requêtes.
FAISS : (Facebook AI Similarity Search)Indexation VectorielleGère l'indexation ultra-rapide des embeddings. Essentiel pour la performance de la recherche.
Phase II : La Requête – Du Contexte à la Réponse Fiable ✨
Lorsqu'une question est soumise (via l'API RESTful), le RAGWorkflow entre dans sa phase d'exécution.
1. Recherche et Récupération (Retrieval)
La question de l'utilisateur est convertie en son propre embedding. Le système utilise alors l'index FAISS pour effectuer une recherche de similarité (par similarité cosinus) et identifier les chunks les plus sémantiquement proches.
- Top-K : Nous déterminons un nombre précis (
top_k) de documents similaires à récupérer. - Filtrage Avancé : Les métadonnées permettent d'affiner la recherche (par exemple, chercher uniquement des documents récents ou sur un thème spécifique).
2. Optimisation Post-Récupération : Le Secret de la Qualité
Avant d'atteindre le LLM, les fragments récupérés passent par une phase d'optimisation critique :
- Stratégie Small-to-Big : C'est une technique puissante. Nous utilisons les petits chunks (512 tokens) pour la recherche de similarité (car ils sont précis), mais nous fournissons des chunks plus longs (incluant le contexte environnant) au LLM pour la génération. Cela donne au modèle un contexte maximal sans sacrifier la précision de la recherche initiale.
- Ranking : Les chunks sont classés par pertinence, s'assurant que les informations les plus importantes arrivent en premier.
3. Synthèse et Génération (Generation)
Les chunks sélectionnés et la question initiale sont combinés pour former un prompt enrichi destiné au LLM (OpenAI).
Le modèle génère alors une réponse qui est :
- Synthétique : Il résume les informations.
- Contextualisée : Il s'appuie uniquement sur les sources fournies.
- Fiable (Grounded) : L'appui sur le corpus contrôlé réduit drastiquement les risques d'hallucination.
- Transparente : Grâce aux métadonnées des chunks, nous pouvons fournir une liste explicite des sources exploitées, renforçant la crédibilité de la réponse finale.
La Fondation Technique (MCP)
Le succès du RAG repose sur l'infrastructure robuste qui le soutient avec comme composants :
Son Workflow
L'orchestrateur central de l'ensemble du pipeline, implémenté en Python.
Ollama
Cette IA a un double rôle : génération des embeddings et génération du texte final.
Redis
Cache intelligent pour stocker les réponses fréquentes et accélérer les performances (TTL configurable).
Gestion Asynchrone & Monitoring
Des opérations asynchrones pour la réactivité, et un logging détaillé pour une robustesse et un monitoring constants.
En conclusion, le RAG n'est pas seulement une nouvelle tendance ; c'est une architecture qui permet de passer d'une intelligence générale à une expertise spécialisée et vérifiable. En transformant des documents non structurés en contexte pertinent (Indexation) pour guider un modèle puissant vers une réponse précise (Requête), notre système s'assure que chaque information sur l'optimisation des nœuds Lightning est ancrée dans la réalité.